Table of Distributions
The following table shows how to rewrite a number of common distributions as exponential-family distributions with natural parameters.
For a scalar variable and scalar parameter, the form is as follows:
For a scalar variable and vector parameter:
For a vector variable and vector parameter:
The above formulas choose the functional form of the exponential-family with a log-partition function . The reason for this is so that the moments of the sufficient statistics can be calculated easily, simply by differentiating this function. Alternative forms involve either parameterizing this function in terms of the normal parameter instead of the natural parameter, and/or using a factor outside of the exponential. The relation between the latter and the former is:
To convert between the representations involving the two types of parameter, use the formulas below for writing one type of parameter in terms of the other.
| Distribution | Parameter(s) | Natural parameter(s) | Inverse parameter mapping | Base measure | Sufficient statistic | Log-partition | Log-partition |
|---|---|---|---|---|---|---|---|
| Bernoulli distribution | p |
|
|
||||
| binomial distribution with known number of trials n |
p | ||||||
| Poisson distribution | λ | ||||||
| negative binomial distribution with known number of failures r |
p | ||||||
| exponential distribution | λ | ||||||
| Pareto distribution with known minimum value xm |
α | ||||||
| Weibull distribution with known shape k |
λ | ||||||
| Laplace distribution with known mean μ |
b | ||||||
| chi-squared distribution | ν | ||||||
| normal distribution known variance |
μ | ||||||
| normal distribution | μ,σ2 | ||||||
| lognormal distribution | μ,σ2 | ||||||
| inverse Gaussian distribution | μ,λ | ||||||
| gamma distribution | α,β | ||||||
| k,θ | |||||||
| inverse gamma distribution | α,β | ||||||
| scaled inverse chi-squared distribution | ν,σ2 | ||||||
| beta distribution | α,β | ||||||
| multivariate normal distribution | μ,Σ | ||||||
| categorical distribution (variant 1) | p1,...,pk where |
where |
|
||||
| categorical distribution (variant 2) | p1,...,pk where |
|
|
||||
| categorical distribution (variant 3) | p1,...,pk where |
|
|
|
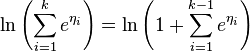 |
||
| multinomial distribution (variant 1) with known number of trials n |
p1,...,pk where |
where |
|||||
| multinomial distribution (variant 2) with known number of trials n |
p1,...,pk where |
|
|||||
| multinomial distribution (variant 3) with known number of trials n |
p1,...,pk where |
||||||
| Dirichlet distribution | α1,...,αk |  |
 |
||||
| Wishart distribution | V,n |
|
|||||
| NOTE: Uses the fact that i.e. the trace of a matrix product is much like a dot product. The matrix parameters are assumed to be vectorized (laid out in a vector) when inserted into the exponential form. Also, V and X are symmetric, so e.g. | |||||||
| inverse Wishart distribution | Ψ,m | |
|||||
The three variants of the categorical distribution and multinomial distribution are due to the fact that the parameters are constrained, such that Thus, there are only independent parameters.
- Variant 1 uses natural parameters with a simple relation between the standard and natural parameters; however, only of the natural parameters are independent, and the set of natural parameters is nonidentifiable. The constraint on the usual parameters translates to a similar constraint on the natural parameters.
- Variant 2 demonstrates the fact that the entire set of natural parameters is nonidentifiable: Adding any constant value to the natural parameters has no effect on the resulting distribution. However, by using the constraint on the natural parameters, the formula for the normal parameters in terms of the natural parameters can be written in a way that is independent on the constant that is added.
- Variant 3 shows how to make the parameters identifiable in a convenient way by setting This effectively "pivots" around and causes the last natural parameter to have the constant value of 0. All the remaining formulas are written in a way that does not access so that effectively the model has only parameters, both of the usual and natural kind.
Note also that variants 1 and 2 are not actually standard exponential families at all. Rather they are curved exponential families, i.e. there are independent parameters embedded in a -dimensional parameter space. Many of the standard results for exponential families do not apply to curved exponential families. An example is the log-partition function A(x), which has the value of 0 in the curved cases. In standard exponential families, the derivatives of this function correspond to the moments (more technically, the cumulants) of the sufficient statistics, e.g. the mean and variance. However, a value of 0 suggests that the mean and variance of all the sufficient statistics are uniformly 0, whereas in fact the mean of the ith sufficient statistic should be (This does emerge correctly when using the form of A(x) in variant 3.)
Read more about this topic: Exponential Family
Famous quotes containing the word table:
“Many a time I have seen my mother leap up from the dinner table to engage the swarming flies with an improvised punkah, and heard her rejoice and give humble thanks simultaneously that Baltimore was not the sinkhole that Washington was.”
—H.L. (Henry Lewis)