Total Derivative, Total Differential and Jacobian Matrix
When f is a function from an open subset of Rn to Rm, then the directional derivative of f in a chosen direction is the best linear approximation to f at that point and in that direction. But when n > 1, no single directional derivative can give a complete picture of the behavior of f. The total derivative, also called the (total) differential, gives a complete picture by considering all directions at once. That is, for any vector v starting at a, the linear approximation formula holds:
Just like the single-variable derivative, f ′(a) is chosen so that the error in this approximation is as small as possible.
If n and m are both one, then the derivative f ′(a) is a number and the expression f ′(a)v is the product of two numbers. But in higher dimensions, it is impossible for f ′(a) to be a number. If it were a number, then f ′(a)v would be a vector in Rn while the other terms would be vectors in Rm, and therefore the formula would not make sense. For the linear approximation formula to make sense, f ′(a) must be a function that sends vectors in Rn to vectors in Rm, and f ′(a)v must denote this function evaluated at v.
To determine what kind of function it is, notice that the linear approximation formula can be rewritten as
Notice that if we choose another vector w, then this approximate equation determines another approximate equation by substituting w for v. It determines a third approximate equation by substituting both w for v and a + v for a. By subtracting these two new equations, we get

If we assume that v is small and that the derivative varies continuously in a, then f ′(a + v) is approximately equal to f ′(a), and therefore the right-hand side is approximately zero. The left-hand side can be rewritten in a different way using the linear approximation formula with v + w substituted for v. The linear approximation formula implies:
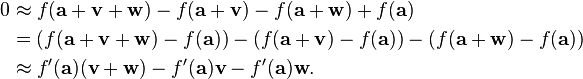
This suggests that f ′(a) is a linear transformation from the vector space Rn to the vector space Rm. In fact, it is possible to make this a precise derivation by measuring the error in the approximations. Assume that the error in these linear approximation formula is bounded by a constant times ||v||, where the constant is independent of v but depends continuously on a. Then, after adding an appropriate error term, all of the above approximate equalities can be rephrased as inequalities. In particular, f ′(a) is a linear transformation up to a small error term. In the limit as v and w tend to zero, it must therefore be a linear transformation. Since we define the total derivative by taking a limit as v goes to zero, f ′(a) must be a linear transformation.
In one variable, the fact that the derivative is the best linear approximation is expressed by the fact that it is the limit of difference quotients. However, the usual difference quotient does not make sense in higher dimensions because it is not usually possible to divide vectors. In particular, the numerator and denominator of the difference quotient are not even in the same vector space: The numerator lies in the codomain Rm while the denominator lies in the domain Rn. Furthermore, the derivative is a linear transformation, a different type of object from both the numerator and denominator. To make precise the idea that f ′ (a) is the best linear approximation, it is necessary to adapt a different formula for the one-variable derivative in which these problems disappear. If f : R → R, then the usual definition of the derivative may be manipulated to show that the derivative of f at a is the unique number f ′(a) such that
This is equivalent to
because the limit of a function tends to zero if and only if the limit of the absolute value of the function tends to zero. This last formula can be adapted to the many-variable situation by replacing the absolute values with norms.
The definition of the total derivative of f at a, therefore, is that it is the unique linear transformation f ′(a) : Rn → Rm such that
Here h is a vector in Rn, so the norm in the denominator is the standard length on Rn. However, f′(a)h is a vector in Rm, and the norm in the numerator is the standard length on Rm. If v is a vector starting at a, then f ′(a)v is called the pushforward of v by f and is sometimes written f*v.
If the total derivative exists at a, then all the partial derivatives and directional derivatives of f exist at a, and for all v, f ′(a)v is the directional derivative of f in the direction v. If we write f using coordinate functions, so that f = (f1, f2, ..., fm), then the total derivative can be expressed using the partial derivatives as a matrix. This matrix is called the Jacobian matrix of f at a:
The existence of the total derivative f′(a) is strictly stronger than the existence of all the partial derivatives, but if the partial derivatives exist and are continuous, then the total derivative exists, is given by the Jacobian, and depends continuously on a.
The definition of the total derivative subsumes the definition of the derivative in one variable. That is, if f is a real-valued function of a real variable, then the total derivative exists if and only if the usual derivative exists. The Jacobian matrix reduces to a 1×1 matrix whose only entry is the derivative f′(x). This 1×1 matrix satisfies the property that f(a + h) − f(a) − f ′(a)h is approximately zero, in other words that
Up to changing variables, this is the statement that the function is the best linear approximation to f at a.
The total derivative of a function does not give another function in the same way as the one-variable case. This is because the total derivative of a multivariable function has to record much more information than the derivative of a single-variable function. Instead, the total derivative gives a function from the tangent bundle of the source to the tangent bundle of the target.
The natural analog of second, third, and higher-order total derivatives is not a linear transformation, is not a function on the tangent bundle, and is not built by repeatedly taking the total derivative. The analog of a higher-order derivative, called a jet, cannot be a linear transformation because higher-order derivatives reflect subtle geometric information, such as concavity, which cannot be described in terms of linear data such as vectors. It cannot be a function on the tangent bundle because the tangent bundle only has room for the base space and the directional derivatives. Because jets capture higher-order information, they take as arguments additional coordinates representing higher-order changes in direction. The space determined by these additional coordinates is called the jet bundle. The relation between the total derivative and the partial derivatives of a function is paralleled in the relation between the kth order jet of a function and its partial derivatives of order less than or equal to k.
Read more about this topic: Derivative, Derivatives in Higher Dimensions
Famous quotes containing the words total, differential and/or matrix:
“... geometry became a symbol for human relations, except that it was better, because in geometry things never go bad. If certain things occur, if certain lines meet, an angle is born. You cannot fail. It’s not going to fail; it is eternal. I found in rules of mathematics a peace and a trust that I could not place in human beings. This sublimation was total and remained total. Thus, I’m able to avoid or manipulate or process pain.”
—Louise Bourgeois (b. 1911)
“But how is one to make a scientist understand that there is something unalterably deranged about differential calculus, quantum theory, or the obscene and so inanely liturgical ordeals of the precession of the equinoxes.”
—Antonin Artaud (1896–1948)
“As all historians know, the past is a great darkness, and filled with echoes. Voices may reach us from it; but what they say to us is imbued with the obscurity of the matrix out of which they come; and try as we may, we cannot always decipher them precisely in the clearer light of our day.”
—Margaret Atwood (b. 1939)