Estimation
Suppose b is a "candidate" value for the parameter β. The quantity yi − xi′b is called the residual for the i-th observation, it measures the vertical distance between the data point (xi, yi) and the hyperplane y = x′b, and thus assesses the degree of fit between the actual data and the model. The sum of squared residuals (SSR) (also called the error sum of squares (ESS) or residual sum of squares (RSS)) is a measure of the overall model fit:
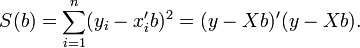
The value of b which minimizes this sum is called the OLS estimator for β. The function S(b) is quadratic in b with positive-definite Hessian, and therefore this function possesses a unique global minimum, which can be given by an explicit formula:

After we have estimated β, the fitted values (or predicted values) from the regression will be
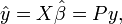
where P = X(X′X)−1X′ is the projection matrix onto the space spanned by the columns of X. This matrix P is also sometimes called the hat matrix because it "puts a hat" onto the variable y. Another matrix, closely related to P is the annihilator matrix M = In − P, this is a projection matrix onto the space orthogonal to X. Both matrices P and M are symmetric and idempotent (meaning that P2 = P), and relate to the data matrix X via identities PX = X and MX = 0. Matrix M creates the residuals from the regression:
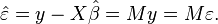
Using these residuals we can estimate the value of σ2:

The numerator, n-p, is the statistical degrees of freedom. The first quantity, s2, is the OLS estimate for σ2, whereas the second, is the MLE estimate for σ2. The two estimators are quite similar in large samples; the first one is always unbiased, while the second is biased but minimizes the mean squared error of the estimator. In practice s2 is used more often, since it is more convenient for the hypothesis testing. The square root of s2 is called the standard error of the regression (SER), or standard error of the equation (SEE).
It is common to assess the goodness-of-fit of the OLS regression by comparing how much the initial variation in the sample can be reduced by regressing onto X. The coefficient of determination R2 is defined as a ratio of "explained" variance to the "total" variance of the dependent variable y:

where TSS is the total sum of squares for the dependent variable, L = In − 11′/n, and 1 is an n×1 vector of ones. (L is a "centering matrix" which is equivalent to regression on a constant; it simply subtracts the mean from a variable.) In order for R2 to be meaningful, the matrix X of data on regressors must contain a column vector of ones to represent the constant whose coefficient is the regression intercept. In that case, R2 will always be a number between 0 and 1, with values close to 1 indicating a good degree of fit.
Read more about this topic: Ordinary Least Squares
Famous quotes containing the word estimation:
“A higher class, in the estimation and love of this city- building, market-going race of mankind, are the poets, who, from the intellectual kingdom, feed the thought and imagination with ideas and pictures which raise men out of the world of corn and money, and console them for the short-comings of the day, and the meanness of labor and traffic.”
—Ralph Waldo Emerson (1803–1882)
“No man ever stood lower in my estimation for having a patch in his clothes; yet I am sure that there is greater anxiety, commonly, to have fashionable, or at least clean and unpatched clothes, than to have a sound conscience.”
—Henry David Thoreau (1817–1862)
“... it would be impossible for women to stand in higher estimation than they do here. The deference that is paid to them at all times and in all places has often occasioned me as much surprise as pleasure.”
—Frances Wright (1795–1852)