How Supervised Learning Algorithms Work
Given a set of training examples of the form, a learning algorithm seeks a function, where is the input space and is the output space. The function is an element of some space of possible functions, usually called the hypothesis space. It is sometimes convenient to represent using a scoring function such that is defined as returning the value that gives the highest score: . Let denote the space of scoring functions.
Although and can be any space of functions, many learning algorithms are probabilistic models where takes the form of a conditional probability model 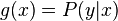 , or takes the form of a joint probability model . For example, naive Bayes and linear discriminant analysis are joint probability models, whereas logistic regression is a conditional probability model.
, or takes the form of a joint probability model . For example, naive Bayes and linear discriminant analysis are joint probability models, whereas logistic regression is a conditional probability model.
There are two basic approaches to choosing or : empirical risk minimization and structural risk minimization. Empirical risk minimization seeks the function that best fits the training data. Structural risk minimize includes a penalty function that controls the bias/variance tradeoff.
In both cases, it is assumed that the training set consists of a sample of independent and identically distributed pairs, . In order to measure how well a function fits the training data, a loss function 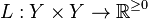 is defined. For training example, the loss of predicting the value is .
is defined. For training example, the loss of predicting the value is .
The risk of function is defined as the expected loss of . This can be estimated from the training data as
- .
Read more about this topic: Supervised Learning
Famous quotes containing the words supervised, learning and/or work:
“It is ultimately in employers’ best interests to have their employees’ families functioning smoothly. In the long run, children who misbehave because they are inadequately supervised or marital partners who disapprove of their spouse’s work situation are productivity problems. Just as work affects parents and children, parents and children affect the workplace by influencing the employed parents’ morale, absenteeism, and productivity.”
—Ann C. Crouter (20th century)
“You taught me language, and my profit on’t
Is, I know how to curse. The red plague rid you
For learning me your language!”
—William Shakespeare (1564–1616)
“I long to be out in the sun with no work to be done.”
—Irving Berlin (1888–1989)