Relationship With k-means
The kernel k-means problem is an extension of the k-means problem where the input data points are mapped non-linearly into a higher-dimensional feature space via a kernel function . The weighted kernel k-means problem further extends this problem by defining a weight for each cluster as the reciprocal of the number of elements in the cluster,

Suppose is a matrix of the normalizing coefficients for each point for each cluster if and zero otherwise. Suppose is the kernel matrix for all points. The weighted kernel k-means problem with n points and k clusters is given as,
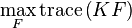
such that,
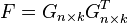
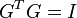
such that . In addition, there are identity constrains on given by,

where represents a vector of ones.

This problem can be recast as,

This problem is equivalent to the spectral clustering problem when the identity constraints on are relaxed. In particular, the weighted kernel k-means problem can be reformulated as a spectral clustering (graph partitioning) problem and vice-versa. The output of the algorithms are eigenvectors which do not satisfy the identity requirements for indicator variables defined by . Hence, post-processing of the eigenvectors is required for the equivalence between the problems. Transforming the spectral clustering problem into a weighted kernel k-means problem greatly reduces the computational burden.
Read more about this topic: Spectral Clustering
Famous quotes containing the words relationship with and/or relationship:
“Some [adolescent] girls are depressed because they have lost their warm, open relationship with their parents. They have loved and been loved by people whom they now must betray to fit into peer culture. Furthermore, they are discouraged by peers from expressing sadness at the loss of family relationships—even to say they are sad is to admit weakness and dependency.”
—Mary Pipher (20th century)
“Some [adolescent] girls are depressed because they have lost their warm, open relationship with their parents. They have loved and been loved by people whom they now must betray to fit into peer culture. Furthermore, they are discouraged by peers from expressing sadness at the loss of family relationships—even to say they are sad is to admit weakness and dependency.”
—Mary Pipher (20th century)