General Multidimensional Distributions
Remember that the cumulative distribution function for a vector of random variables is defined in terms of their joint probability distribution;
The joint distribution for two random variables can be extended to many random variables X1, ... Xn by adding them sequentially with the identity
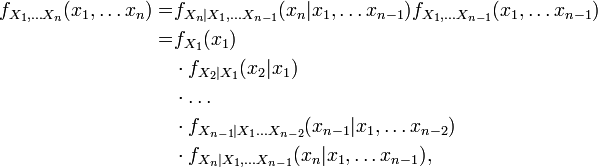
where

and
(notice, that these latter identities can be useful to generate a random variable with given distribution function ); the density of the marginal distribution is
The joint cumulative distribution function is
and the conditional distribution function is accordingly

Expectation reads
suppose that h is smooth enough and for, then, by iterated integration by parts,

Read more about this topic: Joint Probability Distribution
Famous quotes containing the word general:
“Towards him they bend
With awful reverence prone; and as a God
Extoll him equal to the highest in Heav’n:
Nor fail’d they to express how much they prais’d,
That for the general safety he despis’d
His own: for neither do the Spirits damn’d
Loose all thir vertue; lest bad men should boast
Thir specious deeds on earth, which glory excites,
Or close ambition varnisht o’er with zeal.”
—John Milton (1608–1674)