Description
Suppose the available data consists of T iid observations {Yt } t = 1,...,T, where each observation Yt is an n-dimensional multivariate random variable. The data comes from a certain statistical model, defined up to an unknown parameter θ ∈ Θ. The goal of the estimation problem is to find the “true” value of this parameter, θ0, or at least a reasonably close estimate.
In order to apply GMM there should exist a vector-valued function g(Y,θ) such that
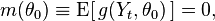
where E denotes expectation, and Yt is a generic observation, which are all assumed to be iid. Moreover, function m(θ) must not be equal to zero for θ ≠ θ0, or otherwise parameter θ will not be identified.
The basic idea behind GMM is to replace the theoretical expected value E with its empirical analog — sample average:
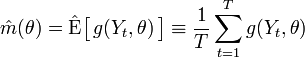
and then to minimize the norm of this expression with respect to θ.
By the law of large numbers, for large values of T, and thus we expect that . The generalized method of moments looks for a number which would make as close to zero as possible. Mathematically, this is equivalent to minimizing a certain norm of (norm of m, denoted as ||m||, measures the distance between m and zero). The properties of the resulting estimator will depend on the particular choice of the norm function, and therefore the theory of GMM considers an entire family of norms, defined as
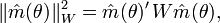
where W is a positive-definite weighting matrix, and m′ denotes transposition. In practice, the weighting matrix W is computed based on the available data set, which will be denoted as . Thus, the GMM estimator can be written as
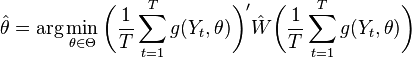
Under suitable conditions this estimator is consistent, asymptotically normal, and with right choice of weighting matrix asymptotically efficient.
Read more about this topic: Generalized Method Of Moments
Famous quotes containing the word description:
“The next Augustan age will dawn on the other side of the Atlantic. There will, perhaps, be a Thucydides at Boston, a Xenophon at New York, and, in time, a Virgil at Mexico, and a Newton at Peru. At last, some curious traveller from Lima will visit England and give a description of the ruins of St Paul’s, like the editions of Balbec and Palmyra.”
—Horace Walpole (1717–1797)
“The type of fig leaf which each culture employs to cover its social taboos offers a twofold description of its morality. It reveals that certain unacknowledged behavior exists and it suggests the form that such behavior takes.”
—Freda Adler (b. 1934)
“Once a child has demonstrated his capacity for independent functioning in any area, his lapses into dependent behavior, even though temporary, make the mother feel that she is being taken advantage of....What only yesterday was a description of the child’s stage in life has become an indictment, a judgment.”
—Elaine Heffner (20th century)