Introduction
Empirical Bayes methods can be seen as an approximation to a fully Bayesian treatment of a hierarchical Bayes model.
In, for example, a two-stage hierarchical Bayes model, observed data are assumed to be generated from an unobserved set of parameters according to a probability distribution . In turn, the parameters θ can be considered samples drawn from a population characterised by hyperparameters according to a probability distribution . In the hierarchical Bayes model, though not in the empirical Bayes approximation, the hyperparameters are considered to be drawn from an unparameterized distribution .
Information about a particular quantity of interest therefore comes not only from the properties of those data which directly depend on it, but also from the properties of the population of parameters as a whole, inferred from the data as a whole, summarised by the hyperparameters .
Using Bayes' theorem,

In general, this integral will not be tractable analytically and must be evaluated by numerical methods; typically stochastic approximations such as from Markov Chain Monte Carlo sampling or deterministic approximations such as quadrature.
Alternatively, the expression can be written as

and the term in the integral can in turn be expressed as
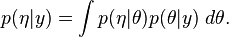
These suggest an iterative scheme, qualitatively similar in structure to a Gibbs sampler, to evolve successively improved approximations to and . First, calculate an initial approximation to ignoring the dependence completely; then calculate an approximation to based upon the initial approximate distribution of ; then use this to update the approximation for ; then update ; and so on.
When the true distribution is sharply peaked, the integral determining may be not much changed by replacing the probability distribution over with a point estimate representing the distribution's peak (or, alternatively, its mean),
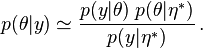
With this approximation, the above iterative scheme becomes the EM algorithm.
"Empirical Bayes" as a label can cover a wide variety of methods, but most can be regarded as an early truncation of either the above scheme or something quite like it. Point estimates, rather than the whole distribution, are typically used for the parameter(s) ; the estimates for are typically made from the first approximation to without subsequent refinement; these estimates for are usually made without considering an appropriate prior distribution for .
Read more about this topic: Empirical Bayes Method
Famous quotes containing the word introduction:
“Do you suppose I could buy back my introduction to you?”
—S.J. Perelman, U.S. screenwriter, Arthur Sheekman, Will Johnstone, and Norman Z. McLeod. Groucho Marx, Monkey Business, a wisecrack made to his fellow stowaway Chico Marx (1931)
“The role of the stepmother is the most difficult of all, because you can’t ever just be. You’re constantly being tested—by the children, the neighbors, your husband, the relatives, old friends who knew the children’s parents in their first marriage, and by yourself.”
—Anonymous Stepparent. Making It as a Stepparent, by Claire Berman, introduction (1980, repr. 1986)
“We used chamber-pots a good deal.... My mother ... loved to repeat: “When did the queen reign over China?” This whimsical and harmless scatological pun was my first introduction to the wonderful world of verbal transformations, and also a first perception that a joke need not be funny to give pleasure.”
—Angela Carter (1940–1992)