Regularization
In machine learning problems, a major problem that arises is that of overfitting. Because learning is a prediction problem, the goal is not to find a function that most closely fits the data, but to find one that will most accurately will predict output from future input. Empirical risk minimization runs this risk of overfitting: finding a function that matches the data exactly but does not predict future output well.
Overfitting is symptomatic of unstable solutions; a small pertubation in the training set data would cause a large variation in the learned function. It can be shown that if the stability for the solution can be guaranteed, generalization and consistency are guaranteed as well. Regularization can solve the overfitting problem and give the problem stability.
Regularization can be accomplished by restricting the hypothesis space . A common example would be restricting to linear functions: this can be seen as a reduction to the standard problem of linear regression. could also be restricted to polynomial of degree, exponentials, or bounded functions on L1. Restriction of the hypothesis space avoids overfitting because the form of the potential functions are limited, and so does not allow for the choice of a function that gives empirical risk arbitrarily close to zero.
Regularization can also be accomplished through Tikhonov regularization. This consists of minimizing
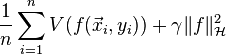
where is a fixed and positive parameter, the regularization parameter. Tikhonov regularization ensures existence, uniqueness, and stability of the solution.
Read more about this topic: Statistical Learning Theory