Derivation
The idea behind LMS filters is to use steepest descent to find filter weights which minimize a cost function. We start by defining the cost function as
where is the error at the current sample 'n' and denotes the expected value.
This cost function is the mean square error, and it is minimized by the LMS. This is where the LMS gets its name. Applying steepest descent means to take the partial derivatives with respect to the individual entries of the filter coefficient (weight) vector

where is the gradient operator.
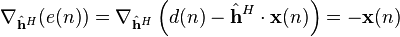
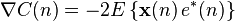
Now, is a vector which points towards the steepest ascent of the cost function. To find the minimum of the cost function we need to take a step in the opposite direction of . To express that in mathematical terms
where is the step size(adaptation constant). That means we have found a sequential update algorithm which minimizes the cost function. Unfortunately, this algorithm is not realizable until we know .
Generally, the expectation above is not computed. Instead, to run the LMS in an online (updating after each new sample is received) environment, we use an instantaneous estimate of that expectation. See below.
Read more about this topic: Least Mean Squares Filter