Implementation
One difficulty with implementing the outlined method is that we cannot take W = Ω−1 because, by the definition of matrix Ω, we need to know the value of θ0 in order to compute this matrix, and θ0 is precisely the quantity we don’t know and are trying to estimate in the first place.
Several approaches exist to deal with this issue, the first one being the most popular:
- Two-step feasible GMM:
- Step 1: Take W = I (the identity matrix), and compute preliminary GMM estimate . This estimator is consistent for θ0, although not efficient.
- Step 2: Take
- Iterated GMM. Essentially the same procedure as 2-step GMM, except that the matrix is recalculated several times. That is, the estimate obtained in step 2 is used to calculate the weighting matrix for step 3, and so on. Such estimator, denoted, is equivalent to solving the following system of equations:
- Continuously Updating GMM (CUGMM, or CUE). Estimates simultaneously with estimating the weighting matrix W:
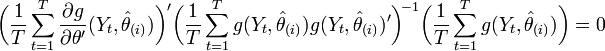

Another important issue in implementation of minimization procedure is that the function is supposed to search through (possibly high-dimensional) parameter space Θ and find the value of θ which minimizes the objective function. No generic recommendation for such procedure exists, it is a subject of its own field, numerical optimization.
Read more about this topic: Generalized Method Of Moments