Rationale
As said, for a random variable with outcomes, the Shannon entropy, a measure of uncertainty (see further below) and denoted by, is defined as
-

(1)
where is the probability mass function of outcome .
To understand the meaning of Eq. (1), first consider a set of possible outcomes (events), with equal probability . An example would be a fair die with values, from to . The uncertainty for such a set of outcomes is defined by
-

(2)
For concreteness, consider the case in which the base of the logarithm is . In order to specify an outcome of a fair -sided die roll, we need to specify one of the values, which requires bits. Hence in this case, the uncertainty of an outcome is the number of bits needed to specify the outcome.
Intuitively, if we have two independent sources of uncertainty, the overall uncertainty should be the sum of the individual uncertainties. The logarithm captures this additivity characteristic for independent uncertainties. For example, consider appending to each value of the first die the value of a second die, which has possible outcomes . There are thus possible outcomes . The uncertainty for such a set of outcomes is then
-

(3)
Thus the uncertainty of playing with two dice is obtained by adding the uncertainty of the second die to the uncertainty of the first die . In the case that this means that to specify the outcome of an -sided die roll and an -sided die roll, we need to specify bits.
Now return to the case of playing with one die only (the first one). Since the probability of each event is, we can write

In the case of a non-uniform probability mass function (or density in the case of continuous random variables), we let
-
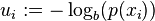
(4)
which is also called a surprisal; the lower the probability, i.e., the higher the uncertainty or the surprise, i.e., for the outcome .
The average uncertainty, with being the average operator, is obtained by
-

(5)
and is used as the definition of the entropy in Eq. (1). The above also explains why information entropy and information uncertainty can be used interchangeably. In the case that, Eq. (1) measures the expected number of bits that we need in order to specify the outcome of a random experiment.
One may also define the conditional entropy of two events X and Y taking values xi and yj respectively, as
where p(xi,yj) is the probability that X=xi and Y=yj. This quantity should be understood as the amount of randomness in the random variable X given that you know the value of Y. For example, the entropy associated with a six-sided die is H(die), but if you were told that it had in fact landed on 1, 2, or 3, then its entropy would be equal to H(die: the die landed on 1, 2, or 3).
Read more about this topic: Entropy (information Theory)