Inference
See also: Dirichlet-multinomial distributionLearning the various distributions (the set of topics, their associated word probabilities, the topic of each word, and the particular topic mixture of each document) is a problem of Bayesian inference. The original paper used a variational Bayes approximation of the posterior distribution; alternative inference techniques use Gibbs sampling and expectation propagation.
Following is the derivation of the equations for collapsed Gibbs sampling, which means s and s will be integrated out. For simplicity, in this derivation the documents are all assumed to have the same length . The derivation is equally valid if the document lengths vary.
According to the model, the total probability of the model is:

where the bold-font variables denote the vector version of the variables. First of all, and need to be integrated out.

Note that all the s are independent to each other and the same to all the s. So we can treat each and each separately. We now focus only on the part.

We can further focus on only one as the following:

Actually, it is the hidden part of the model for the document. Now we replace the probabilities in the above equation by the true distribution expression to write out the explicit equation.
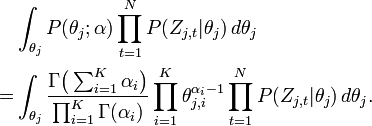
Let be the number of word tokens in the document with the same word symbol (the word in the vocabulary) assigned to the topic. So, is three dimensional. If any of the three dimensions is not limited to a specific value, we use a parenthesized point to denote. For example, denotes the number of word tokens in the document assigned to the topic. Thus, the right most part of the above equation can be rewritten as:

So the integration formula can be changed to:
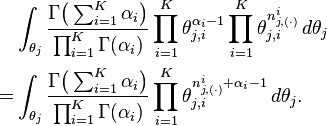
Clearly, the equation inside the integration has the same form as the Dirichlet distribution. According to the Dirichlet distribution,

Thus,

Now we turn our attentions to the part. Actually, the derivation of the part is very similar to the part. Here we only list the steps of the derivation:

For clarity, here we write down the final equation with both and integrated out:
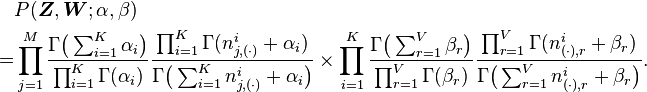
The goal of Gibbs Sampling here is to approximate the distribution of . Since is invariable for any of Z, Gibbs Sampling equations can be derived from directly. The key point is to derive the following conditional probability:

where denotes the hidden variable of the word token in the document. And further we assume that the word symbol of it is the word in the vocabulary. denotes all the s but . Note that Gibbs Sampling needs only to sample a value for, according to the above probability, we do not need the exact value of  but the ratios among the probabilities that can take value. So, the above equation can be simplified as:
but the ratios among the probabilities that can take value. So, the above equation can be simplified as:
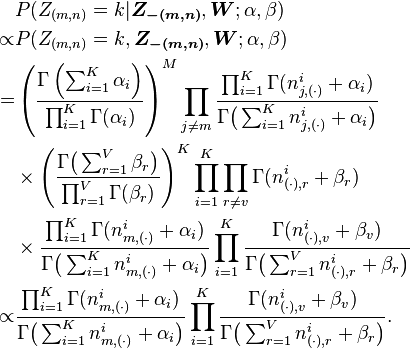
Finally, let be the same meaning as but with the excluded. The above equation can be further simplified by treating terms not dependent on as constants:

Note that the same formula is derived in the article on the Dirichlet-multinomial distribution, as part of a more general discussion of integrating Dirichlet distribution priors out of a Bayesian network.
Read more about this topic: Latent Dirichlet Allocation
Famous quotes containing the word inference:
“I shouldn’t want you to be surprised, or to draw any particular inference from my making speeches, or not making speeches, out there. I don’t recall any candidate for President that ever injured himself very much by not talking.”
—Calvin Coolidge (1872–1933)
“Rules and particular inferences alike are justified by being brought into agreement with each other. A rule is amended if it yields an inference we are unwilling to accept; an inference is rejected if it violates a rule we are unwilling to amend. The process of justification is the delicate one of making mutual adjustments between rules and accepted inferences; and in the agreement achieved lies the only justification needed for either.”
—Nelson Goodman (b. 1906)
“I have heard that whoever loves is in no condition old. I have heard that whenever the name of man is spoken, the doctrine of immortality is announced; it cleaves to his constitution. The mode of it baffles our wit, and no whisper comes to us from the other side. But the inference from the working of intellect, hiving knowledge, hiving skill,—at the end of life just ready to be born,—affirms the inspirations of affection and of the moral sentiment.”
—Ralph Waldo Emerson (1803–1882)