Derivations
Let us have a linear MMSE estimator given as, where we are required to find the expression for and . The orthogonality condition requires the MMSE estimator to be unbiased. This means,
Plugging the expression for in above, we get
where and . Thus we can re-write the estimator as
and the expression for estimation error becomes
From the orthogonality principle, we can have, where we take . Here the left hand side term is
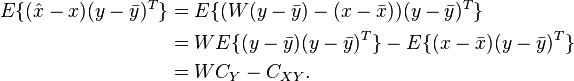
When equated to zero, we obtain the desired expression for as
The is cross-covariance matrix between X and Y, and is auto-covariance matrix of Y. Since, the expression can also be re-written in terms of as
Standard method like Gauss elimination can be used to solve the matrix equation. Since the matrix is a symmetric positive definite matrix it can be solved twice as fast with the Cholesky decomposition. Levinson recursion is a fast method when is also a Toeplitz matrix. This can happen when is a wide sense stationary process.
Thus the full expression for the linear MMSE estimator is
Since the estimate is itself a random variable with, we can also obtain its auto-covariance as

Putting the expression for and, we get
Lastly, the covariance of MMSE estimation error will then be given by
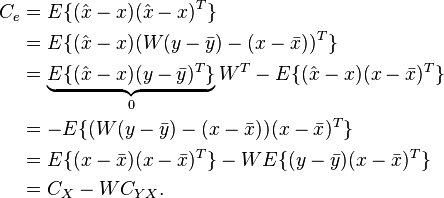
The first term in the third line is zero due to the orthogonality principle. Since, we can re-write in terms of covariance matrices as
This we can recognize to be the same as Thus the minimum mean square error achievable by such a linear estimator is
- .
Read more about this topic: Minimum Mean Square Error, Linear MMSE Estimator