N-gram Models
In an n-gram model, the probability of observing the sentence w1,...,wm is approximated as
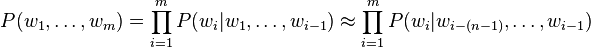
Here, it is assumed that the probability of observing the ith word wi in the context history of the preceding i-1 words can be approximated by the probability of observing it in the shortened context history of the preceding n-1 words (nth order Markov property).
The conditional probability can be calculated from n-gram frequency counts: 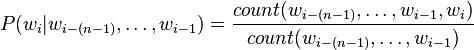
The words bigram and trigram language model denote n-gram language models with n=2 and n=3, respectively.
Typically, however, the n-gram probabilities are not derived directly from the frequency counts, because models derived this way have severe problems when confronted with any n-grams that have not explicitly been seen before. Instead, some form of smoothing is necessary, assigning some of the total probability mass to unseen words or N-grams. Various methods are used, from simple "add-one" smoothing (assign a count of 1 to unseen N-grams) to more sophisticated models, such as Good-Turing discounting or back-off models.
Read more about this topic: Language Model
Famous quotes containing the word models:
“The greatest and truest models for all orators ... is Demosthenes. One who has not studied deeply and constantly all the great speeches of the great Athenian, is not prepared to speak in public. Only as the constant companion of Demosthenes, Burke, Fox, Canning and Webster, can we hope to become orators.”
—Woodrow Wilson (1856–1924)